
Учимся рассуждать с LLM

Мы представляем OpenAI o1 — новую большую языковую модель, обученную с помощью обучения с подкреплением для выполнения сложных рассуждений. o1 думает, прежде чем ответить, — она может создать длинную внутреннюю цепочку мыслей, прежде чем ответить пользователю.
OpenAI o1 занимает 89-й процентиль по вопросам соревновательного программирования (Codeforces), входит в число 500 лучших студентов США в отборочном туре на математическую олимпиаду США (AIME) и превосходит точность уровня доктора философии человека в тесте задач по физике, биологии и химии (GPQA). Хотя работа, необходимая для того, чтобы сделать эту новую модель такой же простой в использовании, как и текущие модели, все еще продолжается, мы выпускаем раннюю версию этой модели, OpenAI o1-preview, для немедленного использования в ChatGPT и для доверенных пользователей API(открывается в новом окне).
Наш масштабный алгоритм обучения с подкреплением обучает модель продуктивному мышлению, используя ее цепочку мыслей в высокоэффективном процессе обучения. Мы обнаружили, что производительность o1 последовательно улучшается с большим количеством обучения с подкреплением (вычисления во время обучения) и с большим количеством времени, потраченного на размышления (вычисления во время тестирования). Ограничения по масштабированию этого подхода существенно отличаются от ограничений предварительного обучения LLM, и мы продолжаем их исследовать.

o1 производительность плавно улучшается как при вычислениях во время обучения, так и при вычислениях во время тестирования
Оценки
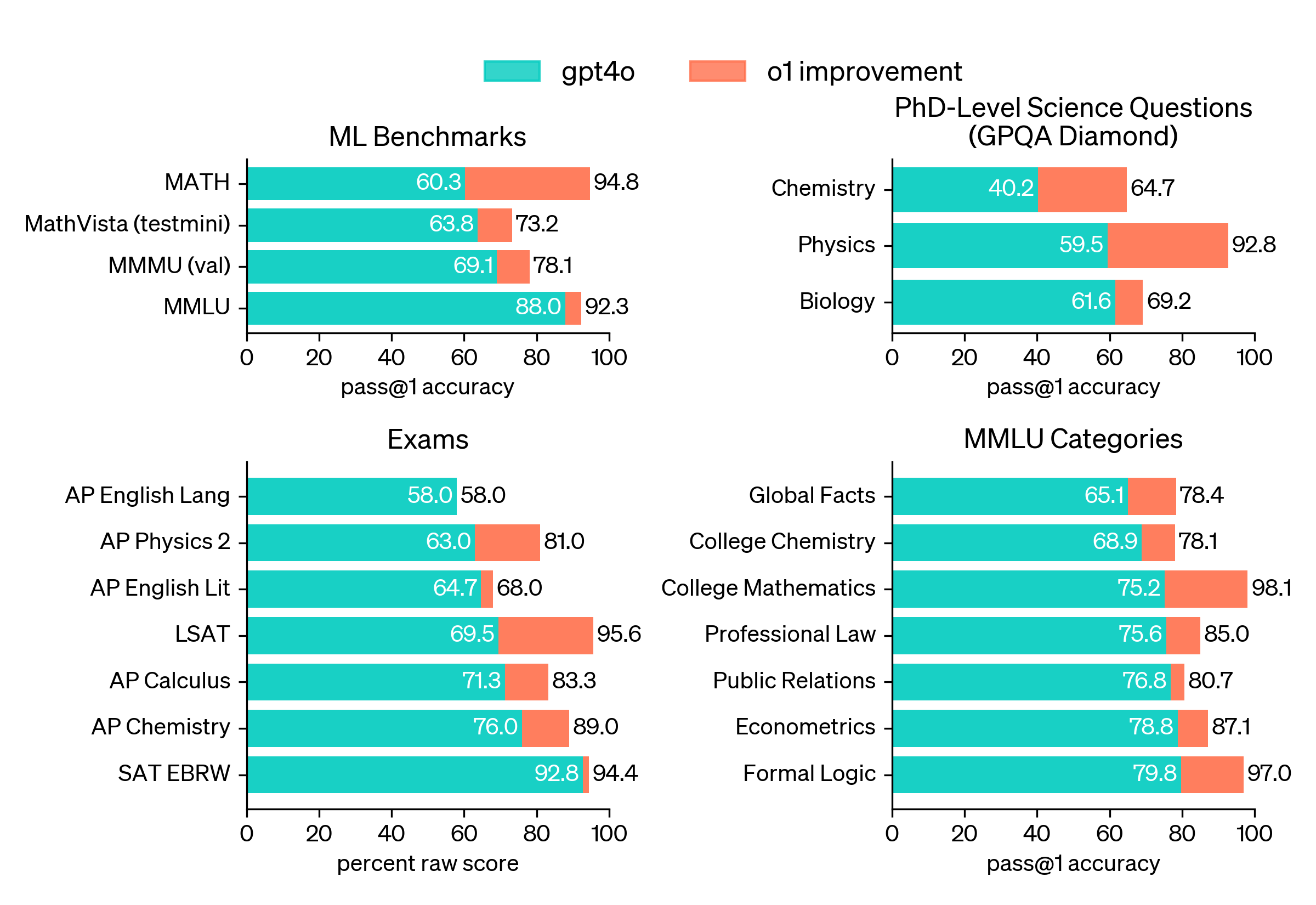
Чтобы подчеркнуть улучшение рассуждений по сравнению с GPT-4o, мы протестировали наши модели на разнообразном наборе человеческих экзаменов и бенчмарков машинного обучения. Мы показываем, что o1 значительно превосходит GPT-4o в подавляющем большинстве этих задач, требующих рассуждений. Если не указано иное, мы оценивали o1 на максимальной настройке вычислений за время теста.
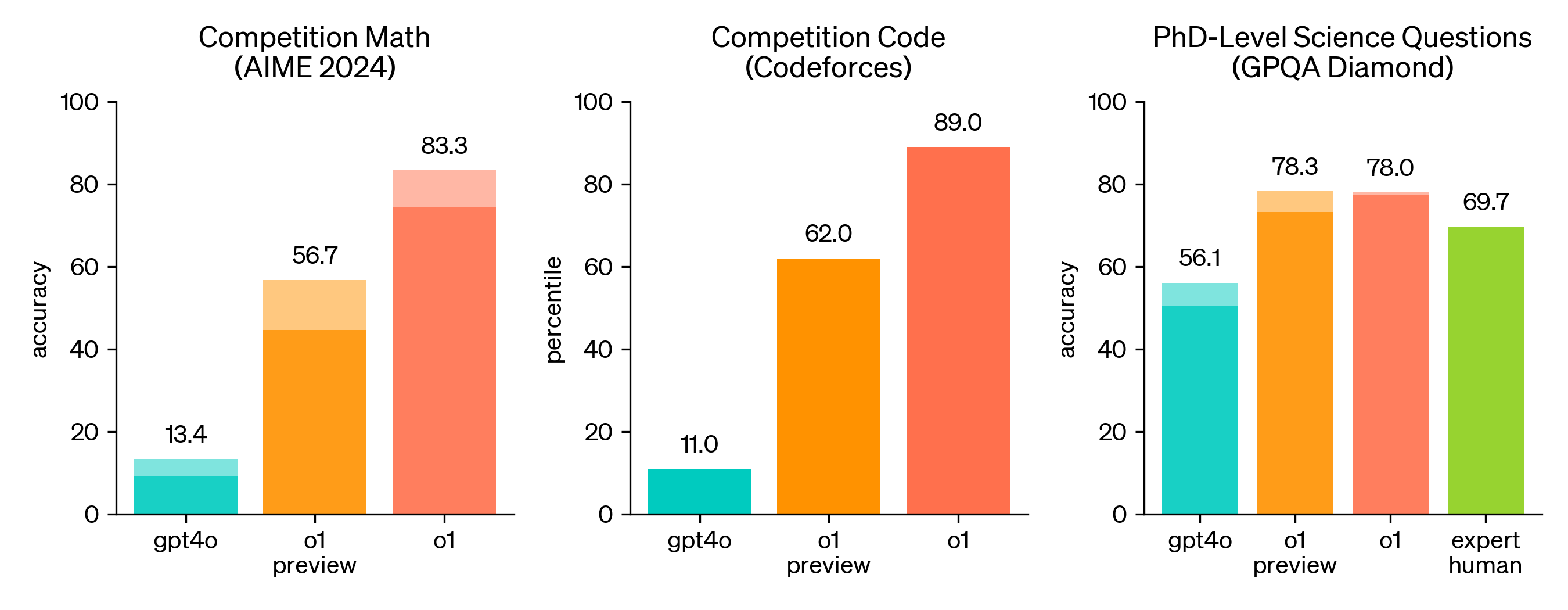
Во многих бенчмарках, требующих больших рассуждений, o1 соперничает с результатами экспертов-людей. Последние передовые модели 1 так хорошо справляются с MATH 2 и GSM8K, что эти бенчмарки больше не эффективны для дифференциации моделей. Мы оценили результаты по математике на AIME, экзамене, разработанном для того, чтобы бросить вызов самым способным ученикам математики старших классов в Америке. На экзаменах AIME 2024 года GPT-4o решил в среднем только 12% (1,8/15) задач. o1 в среднем набрал 74% (11,1/15) с одним образцом на задачу, 83% (12,5/15) с консенсусом среди 64 образцов и 93% (13,9/15) при повторном ранжировании 1000 образцов с помощью усвоенной функции подсчета баллов. Результат 13,9 ставит его в число 500 лучших учеников страны и выше порогового значения для математической олимпиады США.
Мы также оценили o1 по GPQA diamond, сложному тесту интеллекта, который проверяет знания в области химии, физики и биологии. Чтобы сравнить модели с людьми, мы наняли экспертов с докторской степенью для ответа на вопросы GPQA-diamond. Мы обнаружили, что o1 превзошел результаты этих экспертов-людей, став первой моделью, сделавшей это в этом тесте. Эти результаты не означают, что o1 более способен, чем докторская степень, во всех отношениях — только то, что модель более искусна в решении некоторых задач, которые, как ожидается, должен решать докторская степень. В нескольких других тестах МО o1 превзошел самые современные. С включенными возможностями восприятия зрения o1 набрал 78,2% по MMMU, что сделало ее первой моделью, которая может конкурировать с экспертами-людьми. Она также превзошла GPT-4o по 54 из 57 подкатегорий MMLU.
Цепочка мыслей
Подобно тому, как человек может долго думать, прежде чем ответить на сложный вопрос, o1 использует цепочку мыслей, пытаясь решить проблему. Благодаря обучению с подкреплением o1 учится оттачивать свою цепочку мыслей и совершенствовать используемые стратегии. Он учится распознавать и исправлять свои ошибки. Он учится разбивать сложные шаги на более простые. Он учится пробовать другой подход, когда текущий не работает. Этот процесс значительно улучшает способность модели рассуждать. Чтобы проиллюстрировать этот скачок вперед, мы демонстрируем цепочку мыслей из o1-preview по нескольким сложным проблемам ниже.


